Configure Spark Applications
This section shows you how to configure critical aspects of your Spark applications, such as how to control permissions to access data, how to package your code (and install libraries), how to configure the size of your Spark containers, and more.
Before diving into these topics, it is important to realize that the final configuration of a Spark application is the result of applying multiple sources of configuration inputs. By order of precedence:
Source #1: Config Overrides (Highest precedence)
This is an application-specific configuration that you specify directly in your API request. This source of configuration takes precedence over the other sources.
Source #2: Job Configurations
Configurations defined at the level of a job are automatically applied to the future executions of the job. In other words, applications inherit the configurations defined at the job level.
Job configurations are a handy way to define fields such as the mainApplicationFile, the file corresponding to your job. You can also insert specific configurations at this level to improve the performance of your jobs.
For example, if a job requires a lot of memory, you may modify your job configuration to set the instanceAllowList field to target specifically high-memory instances.
Source #3: Auto-tuning
These configurations are applied by Ocean for Spark to improve the performance and stability of your workloads. Some of these optimizations are static. For example, some Spark configurations are adjusted based on the Spark version you selected, while others are dynamically determined by the history of the past executions of a job or the real-time characteristics of your infrastructure. Auto-tuning takes precedence over configuration templates, but is overridden by config overrides.
Source #4: Configuration Templates (Lowest precedence)
These are fragments of configuration that you can define in the Ocean Spark UI or API and then reuse across many notebooks and jobs.
Config Overrides
Config overrides are fragments of configuration that you define when submitting Spark applications through the API. They are specified directly in the body of the POST request (https://api.spotinst.io/ocean/spark/cluster/{clusterId}/app):
curl -k -X POST \
'https://api.spotinst.io/ocean/spark/cluster/<your cluster id>/app?accountId=<your accountId>' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-spot-token>' \
-d '{
"jobId": "spark-pi",
"configOverrides": {
"type": "Scala",
"sparkVersion": "3.2.0",
"mainApplicationFile": "local:///opt/spark/examples/jars/examples.jar",
"image": "gcr.io/ocean-spark/spark:platform-3.2-latest",
"mainClass": "org.apache.spark.examples.SparkPi",
"arguments": ["1000"]
}
Config overrides have higher precedence than all other sources of configuration. As a result, they are useful:
- To specify arguments that change at every execution of your Spark job. For example, if you have an ETL pipeline processing data for a specific date, you should pass this date using config overrides.
- To forcefully ensure a specific configuration is applied (so that it cannot be changed by auto-tuning or a configuration template). For example, you may have a technical reason to force Spark to use a certain codec for compression.
All other configurations are better placed in the configuration templates. To know more about all the configurations you can set, check out the API reference.
Configuration Templates
Configuration templates are fragments of Spark application configuration stored in Ocean Spark. This is useful when you need to share a large default configuration between multiple applications, or to avoid storing configurations on your side.
Following the example above, we'll use a configuration template to store stable configurations, i.e., those that don't change at every execution.
There are two ways you can manage the configuration templates in your deployment: through the Spot Console or through the API.
Spot Console
To manage your configuration templates in the Spot console, go to Ocean for Spark in the menu tree and click Configuration Templates. You should see your current list of configuration templates.
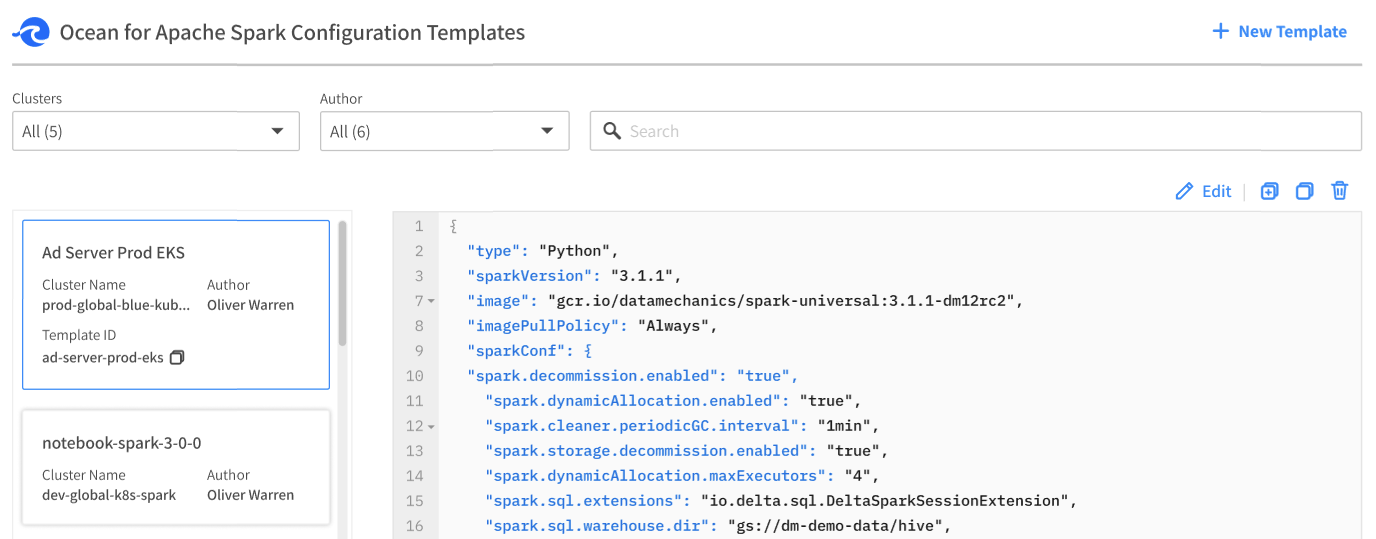
Click on "New Template" in the upper right corner and create a configuration template called my-template with the following content:
{ "sparkVersion": "3.2.0" }
To know more about the all configurations you can set in a template, check out the API reference.
API
The API routes under https://api.spotinst.io/ocean/spark/cluster/{your-cluster-id}/configTemplate let you manage configuration templates as a REST resource.
To know more about the API routes and parameters, check out the API reference.
The following command creates a configuration template with the ID my-template containing this block of Spark application configuration:
curl -X POST \
https://api.spotinst.io/ocean/spark/cluster/<your-cluster-id>/configTemplate \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-spot-token> \
-d '{
"id": "my-template",
"config": {
"sparkVersion": "3.2.0",
}
The configuration template can now be used as a kernel for a Jupyter notebook or referenced when submitting a Spark application using the field configTemplateId:
curl -X POST \
'https://api.spotinst.io/ocean/spark/cluster/<your cluster id>/app?accountId=<your accountId>' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-spot-token> \
-d '{
"jobId": "daily-upload",
"configTemplateId": "my-template",
"configOverrides": {
"type": "Scala",
"mainApplicationFile": "s3a://acme-assets/processing-1.0.0.jar",
"mainClass": "com.acme.processing.DailyUpload",
"image": "gcr.io/ocean-spark/spark:platform-3.2-latest",
"arguments": ["2022-01-01"]
}
Ocean Spark merges the configurations from the configuration template and the config overrides. The configurations in configOverrides have higher precedence than the configuration template.
Job Configurations
Just like configuration templates, you can define job-specific configurations using the Spot console or the API (see API docs).
To edit the configuration for a job from the Spot console, go to Ocean Spark in the menu tree, click on Jobs, find the Job that you're interested in, and then click on the Configuration Tab.
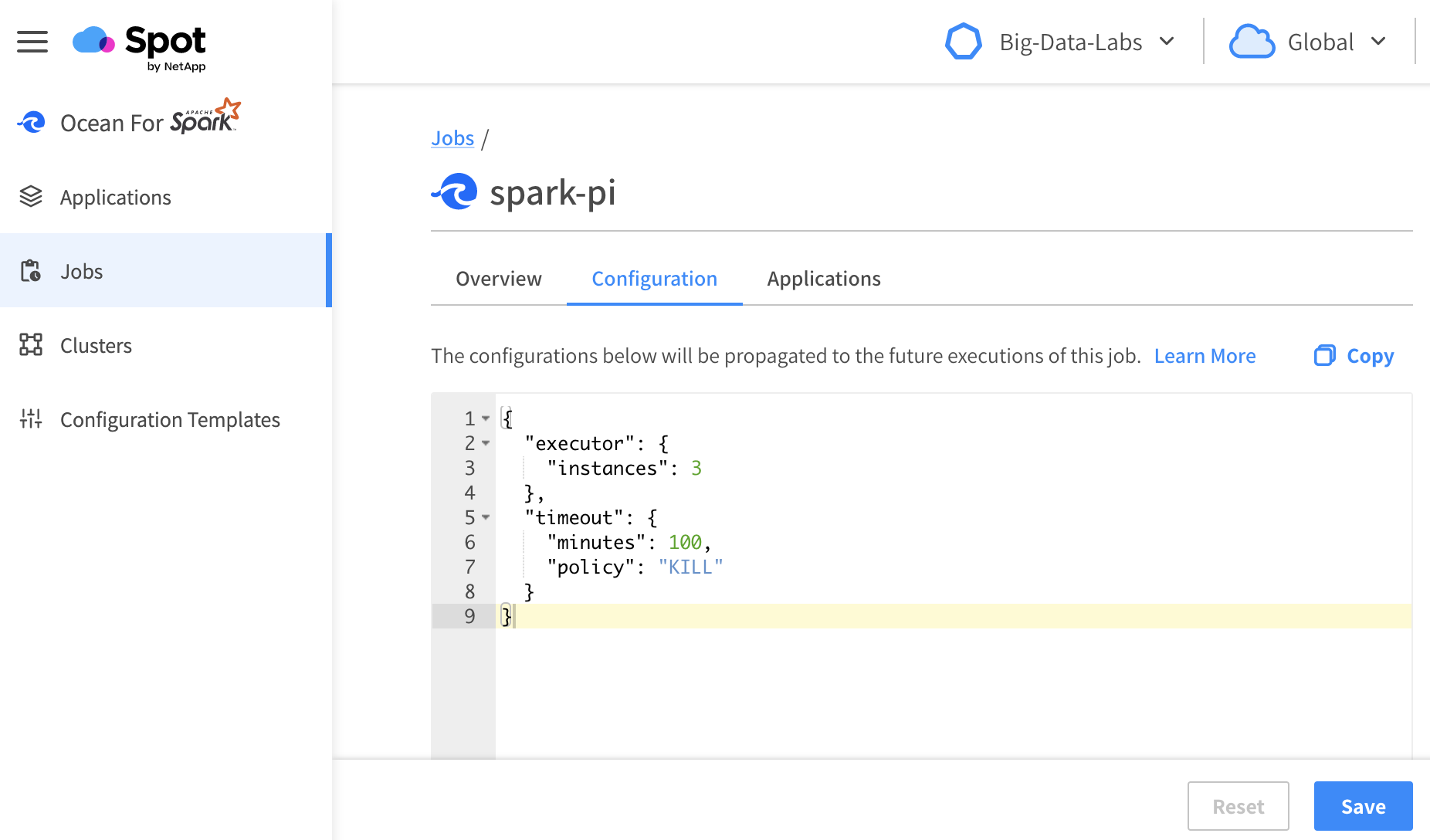
Job configurations have a higher precedence than configuration templates, but a lower precedence than config overrides.
Auto-tuning��
Ocean Spark automatically tunes the infrastructure parameters and Spark configurations of your applications to improve their performance and stability.
Some of these optimizations are static. For example certain sparkConf feature flags are adjusted based on the Spark version you use. Global defaults are also inserted, e.g., to make sure your applications run smoothly and efficiently on Kubernetes.
Other optimizations are dynamically determined by the historical performance of previous executions of your job. After each application finishes, Ocean Spark analyzes the Spark events logs (the logs powering the Spark UI) automatically detect performance inefficiencies or stability issues. This is a dynamic learning process that requires multiple executions of the same workload (grouped within the same Job). Execution after execution, this auto-tuning process continues and adapts to the evolution of your Spark application, without any action on your part.
You can track these automated tuning of configurations by going to the “Configuration” tab of a Spark application and clicking on “Show Sources”. For each configuration, you will see whether it came from a config override, a configuration template, or an auto-tuning setting.
To give you control over the tuning process, the config overrides have precedence over auto-tuning, while configuration templates have not. So if you want to force a parameter (and disable auto-tuning), you can set it in the config overrides. On the other hand, parameters found in configuration templates will be tuned by Ocean Spark when it makes sense. The values you put in the configuration template will serve as a starting point for the algorithm.
For example, if you set the following configuration fragment in the configuration template of your application:
{ "executor": { "instances": 10 } }
Ocean Spark might change the number of executors, in order to improve efficiency of your job. If you put this fragment in the config overrides section of your API call, then the number of executors will never change.
We recommend that you put all performance parameters in a configuration template, so that auto-tuning can adjust them over time.
Related Topics
Learn more about how to access your data.